 布隆过滤器使用
布隆过滤器使用
提示
本项目的所有代码都在 Gitee (opens new window)
# 什么是布隆过滤器
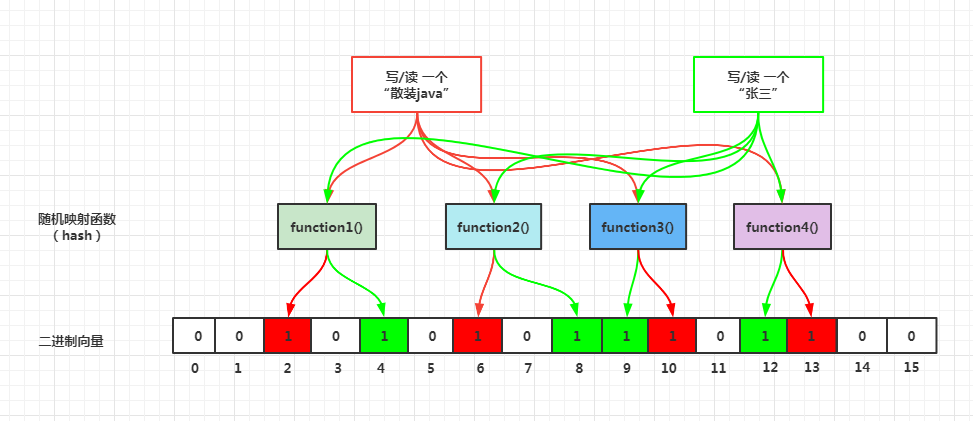
布隆过滤器(Bloom Filter)是1970年由布隆提出的。 它实际上是一个很长的二进制向量 和一系列随机映射函数 。 布隆过滤器可以用于检索一个元素是否在一个集合中 。 它的优点是空间效率和查询时间都比一般的算法要好的多 ,缺点是有一定的误识别率和删除困难 。
ps
上面这句话可以理解为:有个二进制的集合 ,里面存放的0和1,0代表不存在,1代表存在,可以通过一些定义好的方法 快速判断元素是否在集合中。内部逻辑如下图展示
# 布隆过滤器有哪些作用
由于布隆过滤器的特性,能够判断一个数据可能在集合中 ,和一个数据绝对不在集合中 ,所以他可以用于以下场景
- 网页URL的去重(爬虫,避免爬取相同的 URL 地址)
- 垃圾邮件的判别
- 集合重复元素的判别
- 查询加速(比如基于key-value的存储系统)
- 数据库防止查询击穿,使用 BloomFilter 来减少不存在的行或列的磁盘查找(缓存穿透 )。
- ...
# 演示一下布隆过滤器的用法
我这里演示的布隆过滤器的使用,是基于别的轮子 代码都在 Gitee (opens new window)
以下轮子可以使用
- Guava 示例 GuavaBloomFilterTest (opens new window)
- HuTool
- Redisson 示例 RedissonDemoTest (opens new window)
- 自己实现一个 示例 BulkBloomFilter (opens new window)
以及在业务场景的使用案例 ProductController (opens new window)
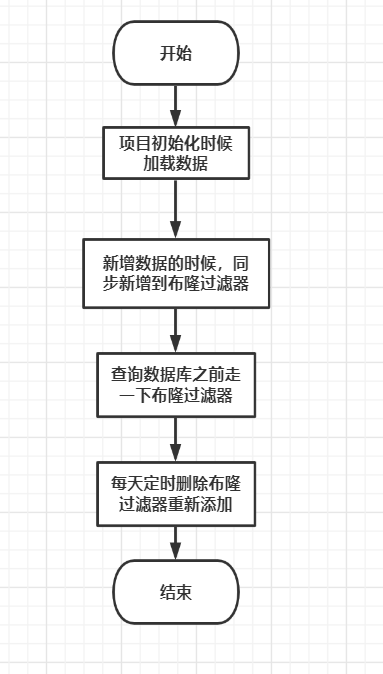
以下为项目中的使用流程
# 如何解决布隆过滤器无法删除数据的问题
- 升级版的布隆过滤器(Counting Bloom Filter) 其原理为:
- 原理就是把位图的位 升级为计数器(Counter)
- 添加元素, 就给对应的Counter分别+1
- 删除元素, 就给对应的Counter分别减一
- 用多出几倍存储空间的代价, 来实现删除功能
- 布谷鸟过滤器(Cuckoo filter)
# 自己实现一个布隆过滤器代码演示
import java.util.BitSet;
/**
* 自定义一个布隆过滤器 (精简版)
*
* @author 散装java
* @date 2022-12-06
*/
public class BulkBloomFilter {
/**
* 一个长度为 10 亿的比特位
*/
private static final int DEFAULT_SIZE = 256 << 22;
/**
* 不同哈希函数的种子,一般应取质数
* 为了降低错误率,使用加法 hash 算法,所以定义一个8个元素的质数数组
*/
private static final int[] SEEDS = {3, 5, 7, 11, 13, 31, 37, 61};
/**
* 相当于构建 8 个不同的 hash 算法 HashFunction 越多,误判率越低,也越慢
*/
private static final HashFunction[] FUNCTIONS = new HashFunction[SEEDS.length];
/**
* 初始化布隆过滤器的 BitSet
* BitSet 即“位图”,是一个很长的 “0/1”序列,他的功能就是存储0或者1
*/
private static final BitSet BIT_SET = new BitSet(DEFAULT_SIZE);
/**
* 添加数据
*
* @param value 需要加入的值
*/
public static void add(String value) {
if (value != null) {
for (HashFunction f : FUNCTIONS) {
//计算 hash 值并修改 bitmap 中相应位置为 true
BIT_SET.set(f.hash(value), true);
}
}
}
/**
* 判断相应元素是否存在
*
* @param value 需要判断的元素
* @return 结果
*/
public static boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (HashFunction f : FUNCTIONS) {
ret = BIT_SET.get(f.hash(value));
// 一个 hash 函数返回 false 就说明这个数据不存在, 则跳出循环
if (!ret) {
break;
}
}
return ret;
}
/**
* 测试
*/
public static void main(String[] args) {
// 初始化 FUNCTIONS
for (int i = 0; i < SEEDS.length; i++) {
FUNCTIONS[i] = new HashFunction(DEFAULT_SIZE, SEEDS[i]);
}
// 添加0到1亿数据
for (int i = 0; i < 100000000; i++) {
add(String.valueOf(i));
}
String id = "123456789";
// 将这个id 放入进去
add(id);
// 查询已经存在的 id 返回 true
System.out.println(contains(id));
// 查询不存在的id 则返回 false
System.out.println("" + contains("100000000"));
}
/**
* 用于计算 hash
*/
static class HashFunction {
/**
* 数组长度 用于限制 hash 生成值的 最大值
*/
private final int size;
/**
* 不同哈希函数的种子,一般应取质数
*/
private final int seed;
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
final int i = (size - 1) & result;
return i;
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
上次更新: 2022/12/10, 19:42:41